

Advances, developments, and innovations in IT solutions bring with them a challenge associated with the emerging consequences and dangers of the automation and process sophistication paradigm, under the premise of "saving time and costs to prioritize more critical and decisive aspects."However, attacks are increasingly sophisticated, automated, and devastating, while the margin for error for defenders has drastically narrowed. According to Prophet (2025), the average time for a ransomware operator to achieve their objectives is just 24 hours after the initial compromise. ¿How many companies could confidently say their teams and adopted security solutions would be prepared to detect and respond coordinately to this class of incidents?
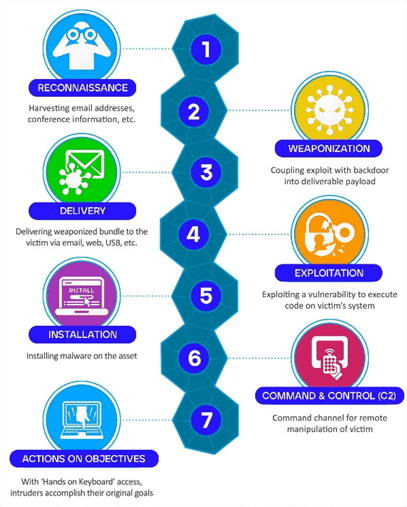
MITRE ATT&CK: A Reference Framework for Both Enthusiasts and Professionals
In the aforementioned context, the best solution lies in coordinating strategies under a panorama of common understanding that is broad enough to segment incidents into phases. This is how MITRE ATT&CK has established itself as the global reference framework for understanding adversary behavior. ATT&CK is a public knowledge base that documents the tactics, techniques, and procedures (TTPs) that adversaries employ in real cyberattacks, based on real-world observations. Its matrix structure organizes nearly 194 behavioral techniques commonly associated with threat actors before data exfiltration and impact, creating a common language that allows defense teams to communicate effectively both internally and with the global cybersecurity community.
From a defensive perspective, this framework acts as a compass in the tasks following threat identification. For example, for a blue team or a SOC (Security Operations Center), the relevance of ATT&CK is multifaceted:
- It allows for the mapping of existing detections against known adversary techniques, revealing gaps in defense coverage.
- It facilitates the prioritization of investments in telemetry and security controls by identifying which techniques pose the greatest risk to the specific organization.
- It provides a framework for validating the effectiveness of detections through adversary emulation exercises. Finally, it enables benchmarking against industry standards, demonstrating the SOC's value to stakeholders with quantifiable metrics. SOC before stakeholders with quantifiable metrics.
Decisions Based on Limited Telemetry: Priorities and Recommendations
Beyond the normative and investigative concept that MITRE frameworkthe major challenges of telemetry can lie in operational costs for those companies that, while trying to take the next step in implementing greater cybersecurity controls, cannot systematically monitor their truly critical assets. The reality is that achieving 100% detection coverage is not only expensive but would be operationally unsustainable due to the volume of alerts and the maintenance burden it would entail.
Based on this statement, the telemetry of these companies should be focused according to real operational constraints. These limitations may include licensing costs per volume of ingested data, storage capacity, network bandwidth for log transfer, configuration complexity in Legacy Systemsor simply the technical maturity of the team.
The Cybersecurity and Infrastructure Security Agency (CISA), in collaboration with the THE FBI, NSA and multiple international agencies, published the "Best Practices for Event Logging and Threat Detection" guide in 2024, which establishes a minimum set of critical events that every organization should capture. Following this publication, the guide prioritizes the following factors:
- Oversight of company-approved logging policies
- Generation of collection and correlation strategies focused on log types, e.g., syslogs.
- Focus on the storage and management of logs based on the CIA (Confidentiality, Integrity, Availability)
- Scheme of detections and behavioral models for relevant threats
When MITRE framework is approached based on the above considerations, it is expected that events within the telemetry can be explained in schemes such as the one shown below:
| Platform | Critical Event Type | Specific Data Examples | MITRE ATT&CK TTP | Priority Level |
| Endpoint (Windows/Linux/macOS) | Successful/Failed Login | Event ID 4624, 4625 (Windows); auth.log (Linux) | Credential Access (T1110), Initial Access (T1078) | High |
| Endpoint | PowerShell/Script Execution | Event ID 4104, 4103 (Windows); process logs | Execution (T1059.001), Defense Evasion (T1027) | High |
| Endpoint | Service Creation/Modification | Event ID 7045, 4697 (Windows); systemd logs | Persistence (T1543), Privilege Escalation | High |
| Endpoint | Credential Access (LSASS) | Event ID 10 (Sysmon); memory access logs | Credential Access (T1003.001) | High |
| Identity/AD | Privileged Group Modification | Event ID 4728, 4732, 4756 (Windows) | Privilege Escalation, Persistence | High |
| Identity/AD | Kerberos Policy Changes | Event ID 4713, 4716 | Credential Access (T1558) | Medium |
| Cloud (AWS/Azure/GCP) | IAM/Permission Changes | CloudTrail (AWS), Azure Activity Log | Privilege Escalation, Persistence | High |
| Cloud | Resource Creation/Modification | API calls to EC2, Storage, Compute | Initial Access, Resource Development | Medium |
| Network | Unusual DNS Traffic | DNS query logs, recursive queries | Command & Control (T1071.004), Exfiltration | Medium |
| Network | Remote SMB/RDP Connections | Network flow logs, firewall logs | Lateral Movement (T1021.001, T1021.002) | High |
| Application | Failed Access to Sensitive Resources | Application-specific authentication logs | Discovery, Collection | Medium |
Towards Continuous Improvement: Evaluation, Feedback, and Necessary Adjustments
Once the elements from the previous example are subjected to an evaluation by the security teams, it is worth addressing the following questions based on a follow-up checklist:
Active Directory and Identity:
- Do we receive authentication logs (successful and failed) from all domain controllers?
- Do we have visibility into changes in administrative groups?
- Do we capture Kerberos and NTLM usage events?
Endpoint:
- What percentage of endpoints has EDR or logging agents installed?
- Do we collect process execution logs with the full command line?
- Do we have PowerShell visibility with Event ID 4104 (Script Block Logging)?
Cloud:
- Is CloudTrail/Azure Activity Log/Cloud Audit Logs enabled in all accounts?
- Do we collect events of changes in IAM and network configuration?
- Do we monitor the creation of resources outside of normal patterns?
Networking:
- Do we have firewall/proxy logs with sufficient granularity?
- Do we capture network flows (NetFlow/IPFIX) for lateral traffic analysis?
- Do we monitor DNS traffic and external connections?
This attack has to date been considered one of the most significant supply chain incidents of 2025not only because of the number of affected packages but because of the temporary disruption of thousands of CI/CD pipelines that depended on them.
What makes this attack particularly dangerous is its self-propagating capability. Once a package was compromised, the malware included a function that automatically downloaded, modified, and injected malicious code into other packages maintained by the same compromised account.
In essence, each infected package became a new distribution point, creating a domino effect throughout the ecosystem.
How to Map an Environment That Needs to Adjust Rules and Make Them More Useful from the MITRE Framework?
The ATT&CK organizes adversary behavior into two main dimensions: tactics and techniques. Tactics represent the adversary's tactical objectives during an attack (the why) while techniques are the specific methods adversaries use to achieve those tactical objectives (the how). Each technique can be mapped to multiple tactics; for example, Process Injection (T1055) aligns with both Defense Evasion and Privilege Escalation.
Because not all behaviors and attacks may be relevant to a company within the framework of its economic activity, infrastructure, and other scopes, it is suggested that security teams focus on techniques and not exclusively on IoCs (Indicators of Compromise), as the latter are easily adaptable for each malicious campaign. It is suggested to review the following steps:
1. Select a Subset of Relevant Techniques
Not all 194+ ATT&CK techniques are equally relevant to every organization. Prioritization should be based on:
- Specific business risk and critical assets
- Threat Intelligence relevant to the sector
- High-priority platforms
- Frequency of use by adversaries
- Existing detection capability
2. Determine Necessary Telemetry per Technique
For each prioritized technique, the team must identify which data sources and specific components would allow its detection. Another example is presented below:
T1021.002 – Remote Services: SMB/Windows Admin Shares
Required Data Sources:
- Logon Session: Logon Session Creation → Event ID 4624 (logon type 3)
- Network Share Network Share Access → Event ID 5140, 5145
- File: File Creation → creation of files in remote shares (\C$, \ADMIN$)
- Process: Process Creation → remote process execution via PsExec or others
Specific Telemetry:
- Windows Security Event ID 4624 (logon type 3, especially with elevated privileges)
- Event ID 4672 (Special Privileges Assigned)
- Event ID 5140/5145 (network share access)
- Sysmon Event ID 3 (Network Connection) for SMB traffic (port 445)
- Sysmon Event ID 11 (File Creation) in administrative share paths
3. Translate Telemetry into Detection Rules
After the telemetry work, we move to the next point, which consists of building the detection logic in an executable format. An example format is SIGMA ruleswhich is an open standard for writing detection rules generically, which can then be translated to multiple backends (Splunk, Elastic, QRadar, Microsoft Sentinel, etc.). If we approach telemetry from the translation to a SIGMA rule, we could visualize an example scheme like the following, which describes PowerShell download and execution cradle behavior:
| title: Suspicious PowerShell Download Cradle |
id: 1f49f2ab-26bc-48b3-96cc-dcffbc93eadf status: stable description: Detects PowerShell download cradles using Invoke-WebRequest or WebClient references: – https://attack.mitre.org/techniques/T1059/001/ author: Blue Team date: 2025-10-29 tags: – attack.execution – attack.t1059.001 – attack.command_and_control – attack.t1071.001 logsource: product: windows category: process_creation detection: selection_powershell: Image|endswith: – ‘\powershell.exe’ – ‘\pwsh.exe’ CommandLine|contains: – ‘Invoke-WebRequest’ – ‘iwr ‘ – ‘wget ‘ – ‘curl ‘ – ‘Net.WebClient’ – ‘DownloadString’ – ‘DownloadFile’ selection_scriptblock: EventID: 4104 ScriptBlockText|contains: – ‘Invoke-WebRequest’ – ‘[Net.WebClient]’ – ‘DownloadString’ condition: selection_powershell or selection_scriptblock falsepositives: – Legitimate administrative scripts – Software deployment tools level: high |
Finally, this rule can be converted to a more concrete and applicable query in other SIEM-type tools, which includes native integrations. This is an example of the SIGMA rules adapted to a query in Splunk:

Image 1. Query equivalent to SIGMA rule, adapted for Splunk SIEM environment
4. Priority Classification
Now, not all alerts have the same impact and operational urgency, so it is suggested to adopt triage for the following events:
| HIGH | MEDIUM | LOW |
| • Critical impact techniques (ransomware, mass exfiltration) • Techniques in advanced stages of the kill chain (Lateral Movement, Exfiltration) • Techniques with full visibility (Visibility_score ≥ 3 according to DeTT&CT) • Techniques frequently used by adversaries (Attacker_score ≥ 75) | • Techniques in early stages (Discovery, some Execution) • Techniques with partial but detectable visibility (1 ≤ Visibility_score < 3) • Techniques of moderate frequency | • Rare or very specific techniques to certain adversaries • Techniques requiring currently unavailable telemetry • Techniques with high false-positive rates without additional context |
Scheme of Responsibilities and Consideration of Essential Metrics
An ATT&CK based detection program requires organizational clarity on who does what. Without defined roles, initiatives stall when key people leave or priorities change. The main organizations that undertake the task of providing SOC services include roles with well-defined responsibilities:
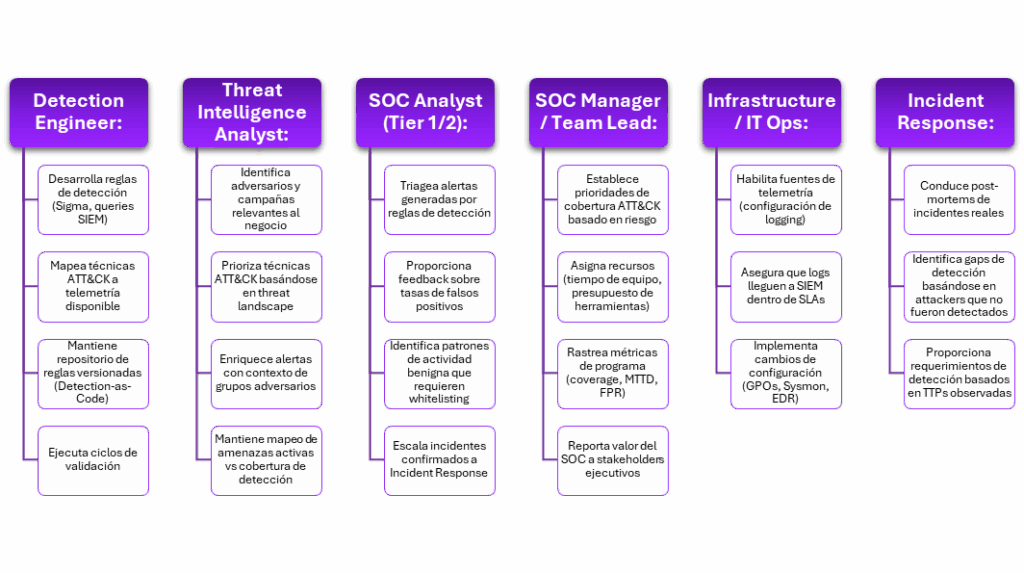
Due to the operational effectiveness must also be considered using tools quantitative, it is useful to adapt rules to continuous improvement and coverage processes. If metrics are approached from the MITRE framework and presented according to tactics, techniques, and procedures, then measurement becomes more efficient with the following metrics:
- Techniques covered (Detection Coverage):
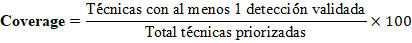
- Coverage by tactic: Percentage of techniques covered within each tactic (Initial Access, Execution, Persistence etc). Allows for the identification of systemic gaps.
- Coverage by platform: Separate coverage for Windows, Linux, Cloud, macOS.
- Number of Active Detections: Total rules/alerts in production.
- Mean Time to Detect (MTTD): Average time from the occurrence of a technique to the generated alert.
- Mean Time to Investigate (MTTI): Average time from alert to determination of true/false positive.
- Mean Time to Remediate (MTTR): Average time from detection to complete containment.
- False Positive Rate per rule:
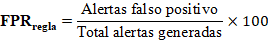
- Coverage delta: Increase in covered techniques compared to the previous quarter.
Conclusion and invitation to the regulatory framework
Implement a detection program based on MITRE ATT&CK with limited telemetry is not a 6-month project with an "end date," but a continuous operational cycle that evolves with threats and the organization. The key steps addressed included:
1. Establish minimum viable telemetry following suggested guidelines.
2. Map coverage ATT&CK
3. Prioritization techniques based on business risk, frequency of use by adversaries, and existing detection capability.
4. Translate technical detections using formats such as portable as Sigma rules
5. Validate detections systematically.
6. Track coverage metrics (Detection Coverage), operational metrics (MTTD, RPF), and continuous improvement to demonstrate value and guide investments.
If your organization has not yet mapped its ATT&CK coveragethe best time to start is now. At 7 Way Security , we have the expertise and capability to provide a comprehensive and adaptive cybersecurity approach, understanding the importance of guiding and supporting those who have decided to take the big step toward strengthening and standardizing their information security efforts.
References:
- Bhatt, U. (2025, June 18). Blue team defense in light of the latest MITRE ATT&CK updates. LinkedIn. https://www.linkedin.com/pulse/blue-team-defense-light-latest-mitre-attck-updates-umang-bhatt-ys9lf
- Torq. (2025, October 22). Automating MITRE ATT&CK analysis with Torq Socrates. Torq Blog. https://torq.io/blog/automate-mitre-attack-analysis/
- Red Canary. (2024, July 29). Mapping detectors to MITRE ATT&CK techniques. Network Canary Blog. https://redcanary.com/blog/security-operations/mapping-detectors-to-mitre-attack-techniques/
- HIPAA Journal. (2024, August 21). CISA & partners issue guidance & best practices for event logging and threat detection. HIPAA Journal. https://www.hipaajournal.com/guidance-best-practices-for-event-logging-threat-detection/
- Prophet Security. (2025, May 6). SOC metrics & KPIs that matter: MTTR, MTTD, MTTI, false negatives, and more. Prophet Security Blog. https://www.prophetsecurity.ai/blog/soc-metrics-that-matter-mttr-mtti-false-negatives-and-more
- Red Canary. (2025, March 16). PowerShell: Technique analysis and detection guidance. Network Canary Threat Detection Report. https://redcanary.com/threat-detection-report/techniques/powershell/
- MITRE. (n.d.). Adversary emulation plans. MITRE ATT&CK®. https://attack.mitre.org/resources/adversary-emulation-plans/


